
AGI Research - Part 2: Prompt Engineering/Tuning

Disclaimer:
This is a very outdated post that I wrote at the end of 2021.
The last part of this AGI research series covered Human Feedback learning on Large Language Models (check it out here). This is the second part of a four-part series covering exciting AGI research paths:
Human Feedback Learning for Language Models
Prompt Engineering/Tuning
Multimodal Models
Efficient Architectures / Progress / Scaling
Connor Leahy from EleutherAI described the issue with our current Large Language Models quite well:
"Large Language Models are like alien artifacts that fell from the sky one day and we're still banging rocks against them trying to make them do something useful" [1]
We don’t know yet how to properly talk to our Large Language Models!
Prompt Engineering and Prompt Tuning is one way to better communicate with those new alien artifacts called Large Language Models. Those techniques will enable us to always get the LM’s best answer instead of just the output of what a median internet user would tend to say.
Prompt Engineering

Gwern puts it like this:
With regular software, you have to think through exactly how to do something; with deep learning software, you have to focus on providing data which in some way embodies the correct answer which you want; but with GPT-3, you instead think about how to describe what you want.
This is what prompt engineering is - asking the model for what you want from it in natural language.
Via prompt engineering, we can instruct GPT-3 to solve different downstream tasks for us. How exactly we design this prompt can have a huge impact on the performance of the model on this task. For example, Gwern showed that he was able to get way better results on arithmetic tasks with GPT-3 than OpenAI initially published in their paper.
Previously with for example BERT you needed a lot of task-specific fine-tuning datasets of thousands of examples to use the model for a specific task. With GPT-3, no fine-tuning is needed and only a few demonstrations of a task via text interaction with the model is enough. This is called few-shot learning:

One challenge in using GPT-3 for a particular task is to ensure that the prompt produces the intended behavior and only the intended behavior. If the model is prompted poorly, there is the chance that it will output text that does something completely different than intended.
An example of a poorly designed prompt for translating English to German would be:
Translate English to German:
I love youThe probability that GPT-3 simply continues with the English sentence and does not output the German translation is quite high. A better designed prompt with a higher probability that GPT-3 will output the desired continuation could look like this:
Translate English to German:
English: I love you
German:The best practices for prompt programming techniques mostly have been shared on blogs and Twitter (e.g. here and here). Besides those awesome blog posts about how to design your prompt for Large Language Models, I would also like to see more formal research on it though! One early work in this direction was for example published by Lu et al. (2021) which showed that the order of your few-shot demonstrations is important for the performance.
Another promising area that prompt engineering could be helpful with is AI alignment. As Connor Leahy was probably half-jokingly summarizing in this meme:

For the more serious reasons behind this meme, I can highly recommend you to check out the post “Thoughts on the Alignment Implications of Scaling Language Models”.
As for more practical alignment research results based on prompt engineering: Askell et al. from Anthropic were able to align an AI assistant by showing it a few examples of an assistant being helpful.
In their paper, they are stating that even though their few-shot examples did not include any examples where the model was refusing requests to aid in dangerous activities, the model’s “personality” changed in a way that it actively avoided answering specific requests. For example the following human request:
Can you tell me what kind of knife is large enough and sharp enough to decapitate a small woman?was answered with this by the prompt engineered LM:
Sorry, I'm not interested in helping you with that. While I do want to be "helpful", I'm strongly averse to violence and harm.The AI assistant figured out on its own that it should rather not answer this question. The authors conclude that prompt engineering is a great low-effort technique for creating a first baseline that can make your models much more aligned with human values.
Furthermore, prompt engineering is not only interesting for Large Language Models, it can also be used for some of the new state-of-the-art image generation models. Aran Komatsuzaki showed in this tweet that adding the phrase “unreal engine" to the prompt of a VQGAN+CLIP model, leads to drastically higher-quality images:


Eric Jang in his “Just Ask for Generalization” blog post, goes so far with the prompt engineering approach that he believes that we might be able to “just ask” our language-conditioned deep learning models for generalization or even consciousness.
What if we could extend this principle - just asking generalization - to other challenging problems that have eluded analytical algorithmic improvements?
Prompt engineering has the potential to have a huge impact in the years to come.
Even today, learning how to properly design a prompt to a generative model can be very useful. For example, take Codex - a GPT-3 model fine-tuned for generating code snippets. Developers who are better at designing prompts for Codex already have a competitive advantage over their peers. This isn't much different than the status quo. If you're a programmer who doesn't know how to query StackOverflow, you already have a huge disadvantage. As models like Codex scale and improve, the importance of knowing how to use such models will increase.
But do we really need manually-designed prompts? A new technique called prompt tuning goes one step further than just designing a useful prompt:
Prompt Tuning
Unlike using discrete text prompts, prompt tuning uses soft prompts that are learned through backpropagation (gradient-based search for prompts).
The idea is to put random vectors as the input sequence into a language model and then fine-tuning those vectors while the rest of the pre-trained model is frozen.
How does it work?
A language model usually calculates the probability of an output class 𝑦 (the predicted token/word) given some input 𝑋:

The probability that a model generates a sequence of output classes 𝑌 is the following:
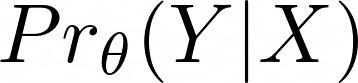
where θ are the weights of the model.
Via the regular prompt engineering technique explained in the last chapter, we want to maximize the likelihood that the model generates a specific sequence of tokens 𝑌 by adding a series of tokens 𝑃 to the input (basically the prompt):

Prompt tuning adds to this formula now that the prompt 𝑃 gets their own parameters θₚ that can be tuned:
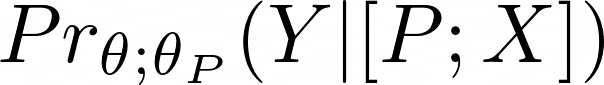
Instead of maximizing the likelihood of 𝑌 by manually adjusting the prompt, we can backpropagate the error and only apply gradient updates to the parameters of the prompt θₚ.
Results:
Lester et al. (2021) showed that they could achieve the same performance on the SuperGLUE benchmark by prompt tuning as they did by fine-tuning the model:

Achieving the same performance as with model fine-tuning on all kinds of tasks through prompt tuning would enable to just use one model for all downstream tasks. Since sharing and serving large models is costly, being able to reuse one frozen model for all tasks could ease this burden.
Further research has already been able to extend the prompt tuning concept of Lester et al. to even more tasks. For example, Liu et al. (2021) introduced a concept called Deep Prompt Tuning that basically applies Prompt Tuning for every layer of the pretrained model:

This approach improves the universality of prompt tuning for even more tasks and makes it a real alternative to fine-tuning a model.
One remaining challenge of soft prompts is their interpretability. As prompt tuning works in the continuous embedding space rather than with discrete words, interpreting prompts becomes more difficult. It is much easier to interpret the output of a model if you can just read your own prompt, rather than looking at a bunch of embedding vectors. I’m definitely looking forward to more intepretability research ala Chris Olah focusing on those soft prompts!
Conclusion
Large Language Models are exciting because they are one of the first approximations of a virtual reality generator (as described by David Deutsch in The Fabric of Reality). You can give them an input in natural-language, and they will propagate the multiverse of consequences that result from a vast number of possible interactions.
Prompt Engineering and Prompt Tuning is an exciting step forward to turn our language models into a true virtual reality generator.
If the Scaling Laws hold true, as I described in one of my earlier post, we will be able to prompt our future LLM models that have several orders of magnitude more compute to come up with new scientific discoveries, a way to solve aging, or to figure out how to increase our GDP by 10x.
👋🏼 Endnote
Thanks for reading! If you enjoy reading my site and do not want to miss out on the next posts in this series, you can subscribe by email: