
Scaling Hypothesis - The path to Artificial General Intelligence?

Disclaimer:
This is a very outdated post that I wrote at the beginning of 2021.
The last couple of months I went down the rabbit hole of understanding the workings of GPT-3, the language model that got a lot of hype in the summer of 2020.
During my research to understand the technical implementations of GPT-3, I got most fascinated by this blog post by Gwern about the Scaling Hypothesis of Language Models. If you didn't read it yet, go there now, because it's awesome! Otherwise here is a summary in my own words:
Scaling Hypothesis and GPT-3 Explanation
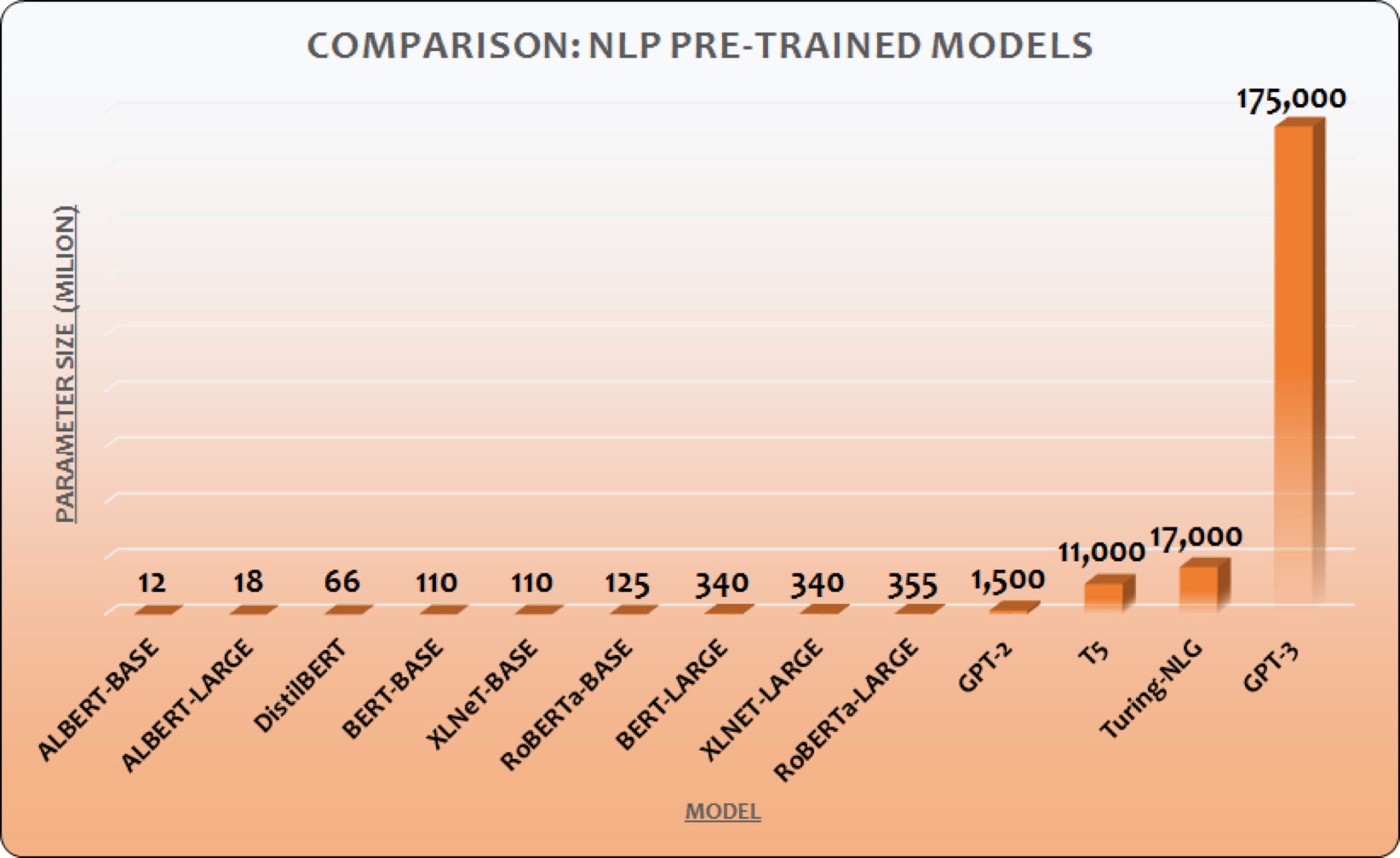
GPT-3 is a language model created by OpenAI. It has over 10x more parameters than the second biggest language model.
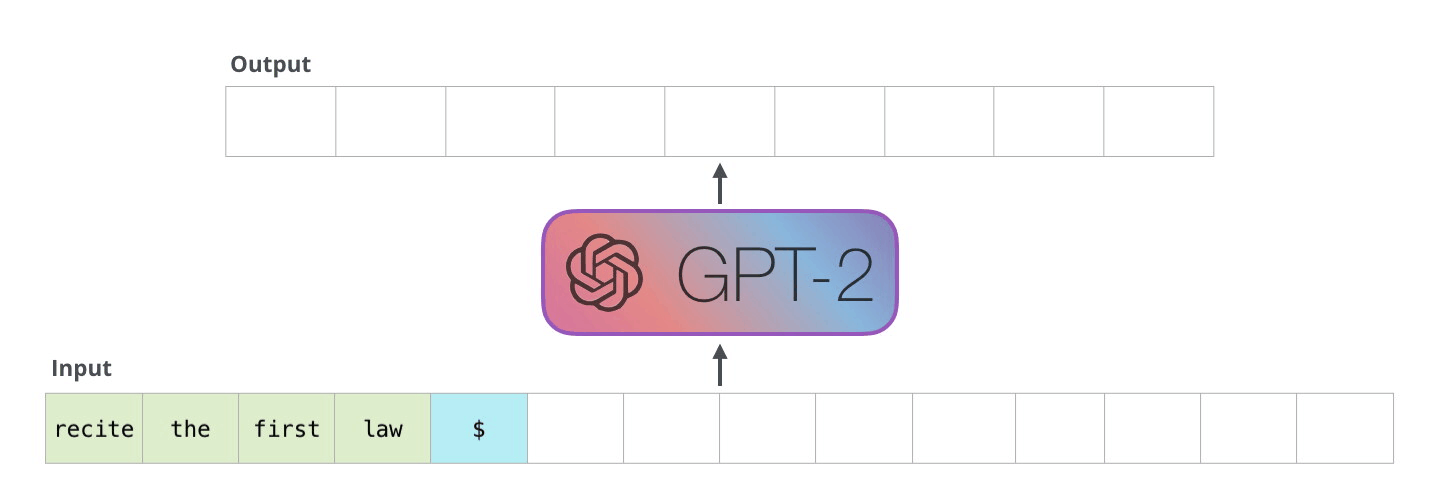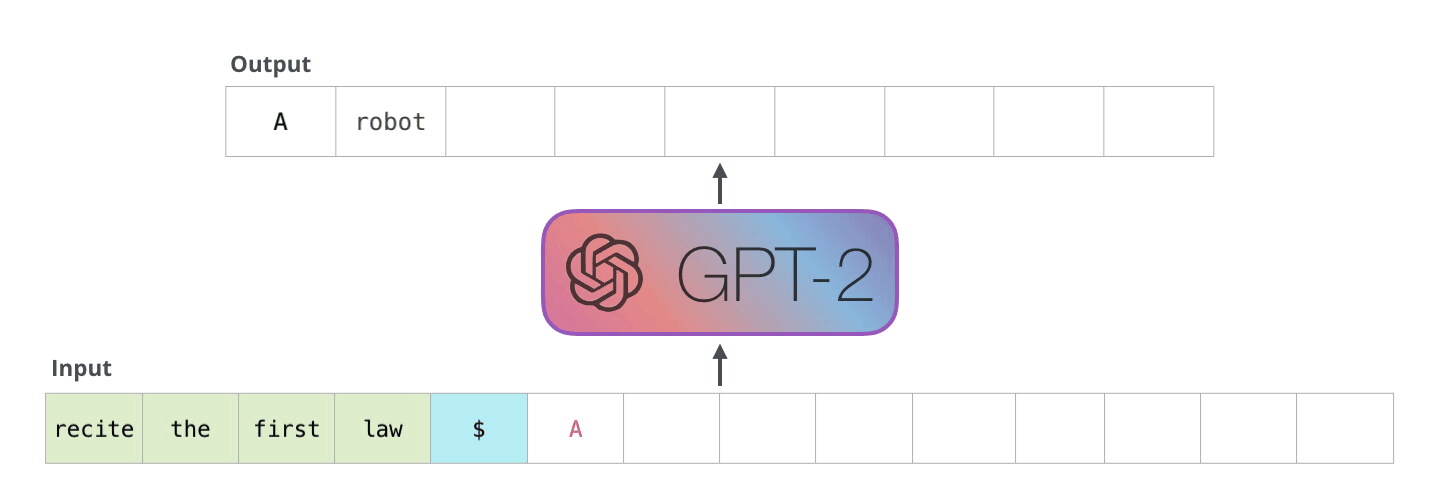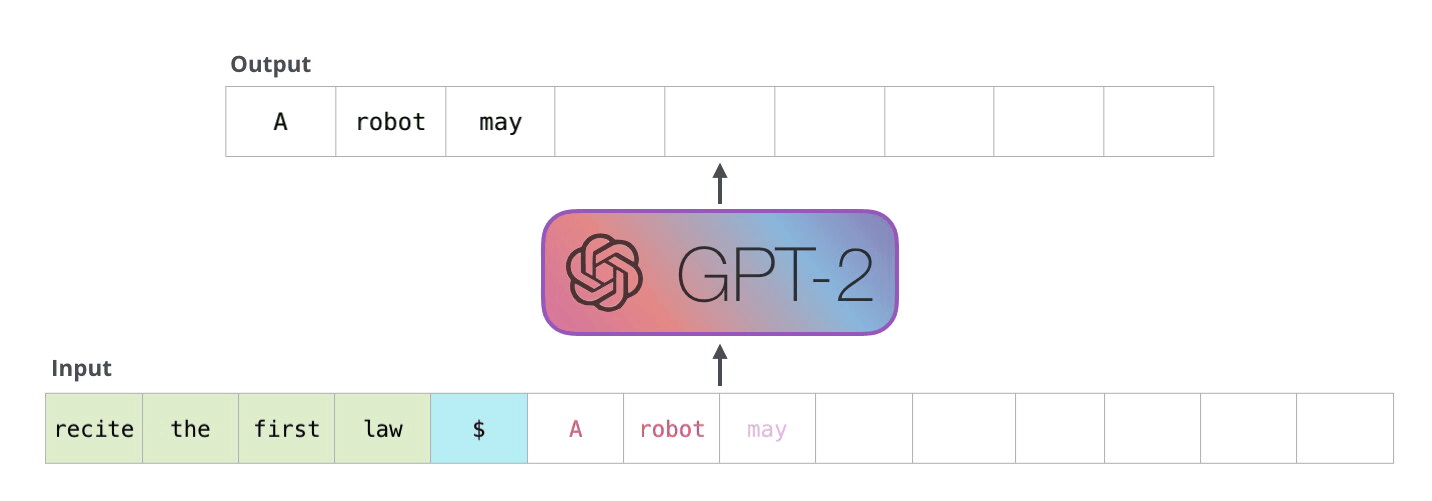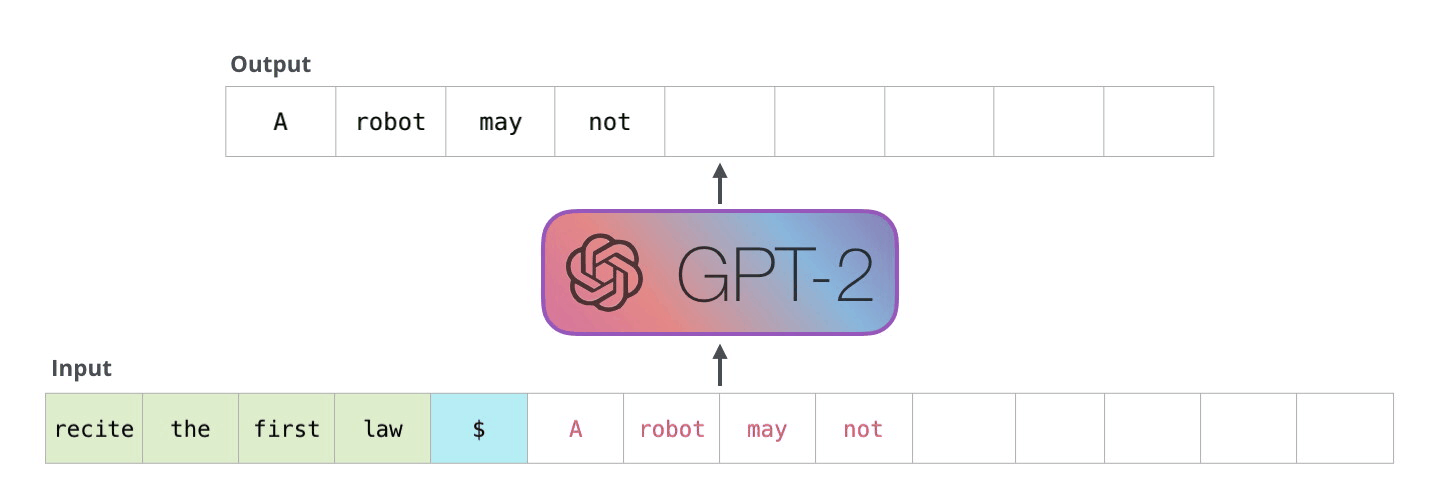
The model was pre-trained on, what is basically, a scrape of the whole internet (The Common Crawl dataset). During this pre-training process, parts of this huge text data set were fed into the model and it was simply asked to predict what the next word of this text would be:
The specific cost for training the model wasn't disclosed. However, estimates put the cost at around $4.6 million based on running the model on the cheapest V100GPUs.
The results of GPT-3 were astonishing. It manages to outperform supervised state-of-the-art models on several tasks without the need for fine-tuning.
Beyond the model's impressive memorization capability, it has shown promising abilities to perform meta-learning (learning to learn) just by showing it a few examples of a new task. To produce results that illustrate this capability the team at OpenAI introduced several new tasks that require the model to detect novel patterns.
One of the chosen tasks was arithmetic, which nobody taught the model. Being able to do even simple operations like addition, subtractions and multiplication would demonstrate the model’s ability to learn new tasks on its own. GPT-3 was able to do just that. This ability to meta-learn is the basis for the scaling hypothesis.
If you are interested in learning more about how GPT-3 works, check out my video about the paper presentation of the model:
The theory that I briefly touched on at the end of my video and that was in detail explored by Gwern is the Scaling Hypothesis. It focuses on the question if we could scale a simple model like GPT-3 even further in model size and training data to achieve human-level performance on almost all tasks (aka achieving Artificial General Intelligence).
They trained 8 different sizes of GPT-3 models for comparison. The smallest is 125M parameters, the biggest one, that all the hype is about, has 175B parameters.
The following diagram shows the loss of the different models OpenAI created:
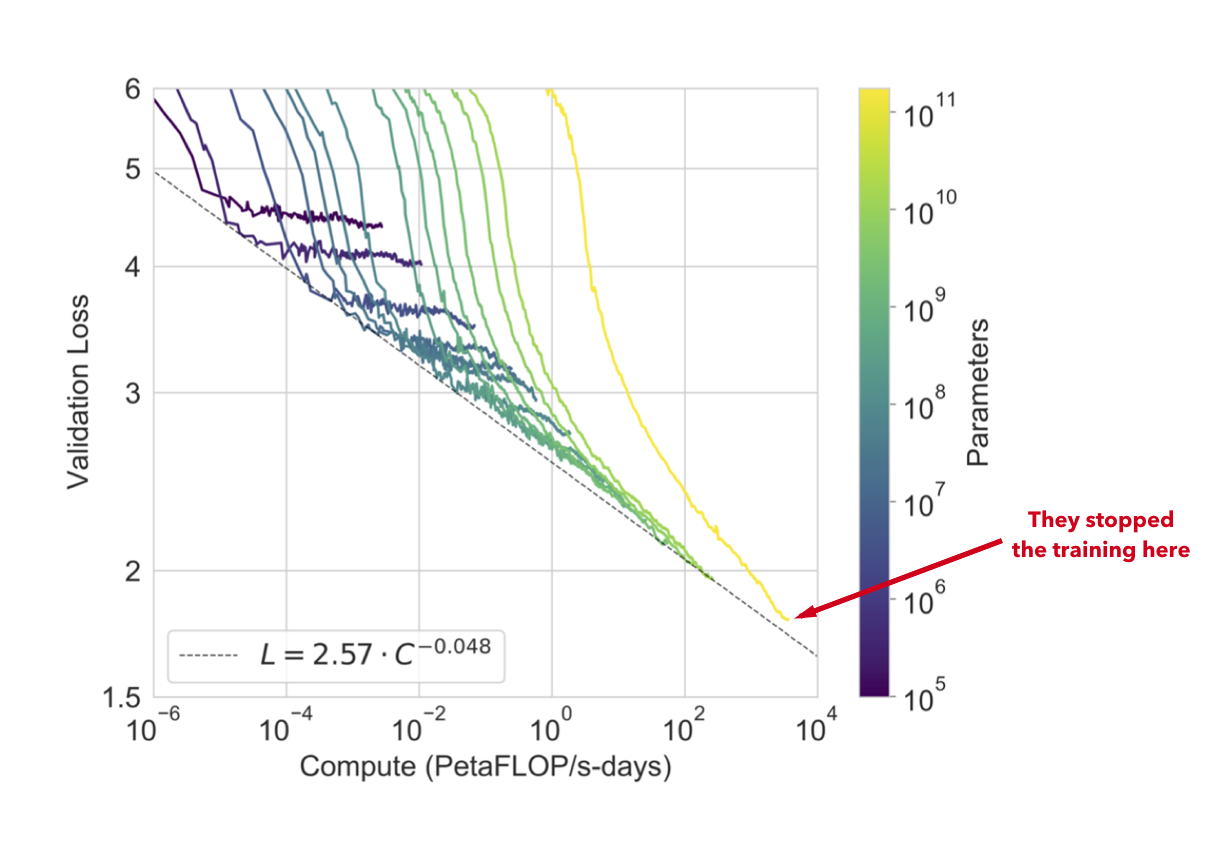
Even the yellow line of the largest GPT-3 model does not seem to flatten out where OpenAI stopped training the model. So there is no sign that an even larger language model wouldn't create an even lower loss value.
This leads us to the scaling hypothesis. This one claims that the secret of general intelligence lies in simple neural units and learning algorithms applied to diverse experiences at a (currently) unreachable scale. Thus, the more we increase the computational resources with which we train our models, the more intelligent they become.
The above-mentioned phenomenon could already be seen in GPT-3. The larger models were able to generalize better without the need to update the underlying architecture.
So let's assume the Scaling Hypothesis is true and models continue to perform better if they scale in model size and data. When will we reach Artificial General Intelligence?
According to Gwern's calculations on the results on all the different tasks, GTP-3 has somewhere around twice the absolute error of a human. So if the current scaling laws continue to be true, we would need around 2,200,000× the compute of GPT-3 to achieve human-level performance.
This isn't quite feasible to do at this moment of time ($4.6M * 2,200,000 ~ $10 trillion → It would cost us around 5 US Covid-19 relief packages). However, if the trend that has persisted since 2012 continues that the amount of compute needed to train a neural net decreases by a factor of 2 every 16 months, we would be able to train a model with 2,200,000× the compute of GPT-3 for $1B in 2038.
So according to this hypothesis, a realistic prediction for when we will be able to build an AGI is in the late 2030s.
This got me interested in the whole topic. Why should someone have the incentive to build a larger language model? Who believes in this hypothesis and who is already working on scaling up language models rapidly? What do the critics say?
Why building a larger language model makes sense
For Natural Language Processing standards GPT-3 is probably the most expensive model that was ever trained. On the other side, the estimated $4.6M of training cost is super cheap in military/government budget standards (The US military burns $4.6M every 3.2 minutes).
Even at current computation scales, it could make sense to spend a few billion on building a model with trillions of parameters to build a stronger language model than GPT-3.
Therefore, I wouldn’t be surprised if nation states or secret services already trained even larger and powerful language models than GPT-3.
I’m not saying that governments or secret services already have some kind of AGI, but possibly a language model trained on even more parameters with way better performance.
When I mentioned that possibility to some friends, they were quite confused and asked what governments or secret services would need a language model for.
My answer was that besides all the "good" intentions that they could use it for (e.g. increasing productivity on internal processes), there are a lot of potential misuses. An example would be the ability to create super-realistic Twitter bot accounts to spread propaganda.
But if you don't trust me, let's look at what the GPT-3 paper has to say about the possible misuses of language models:
Any socially harmful activity that relies on generating text could be augmented by powerful language models. Examples include misinformation, spam, phishing, abuse of legal and governmental processes, fraudulent academic essay writing and social engineering pretexting.
I have to admit that since most researchers don’t believe in the scaling hypothesis (yet), I give my little conspiracy theory a pretty low chance (<5%). All that matters is that it might be financially worthwhile for them to do it.
Critics
Amongst researchers, the Scaling Hypothesis is still quite an unpopular theory. So let's look at some arguments by researchers/engineers that don’t believe in the Scaling Hypothesis:
François Chollet from DeepMind on the Lex Fridman Podcast:
He says that there isn't enough training data out there. GPT-3 was already trained on almost all the data on the internet (Common Crawl).
GPT-3 was trained on Common Crawl only 0.44 times, so it didn't even see the whole dataset. Wouldn't it be beneficial if it would see the data a few times? Yes. So data-wise the GPT series should be good for another 30-40x scale-up.
Another option would be to pre-train GPT on other data than just text, e.g. image/video data.
Furthermore, the data on the Internet doubles every ~5 years (I couldn’t find any sources that were able to confirm that this is true for text data on the internet too, but it is reasonable to assume that it is following a similar growth rate). Given enough time and continuous exponential growth, the training data bottleneck problem would solve itself.
George Hotz Comments about GPT-3 on the Lex Fridman Podcast:
“We're not just gonna be able to scale up to GPT-12 and get general purpose intelligence like your loss function is literally just Cross-Entropy Loss on the character. That's not the loss function of general intelligence“
To counter his argument, I can only refer to this quote:
“A wise man once told me that inexperienced engineers tend to undervalue simplicity.”
~ https://jacobjackson.com/cross-entropy/ (Definitely check out this blog post, if you want to know why the Cross-Entropy Loss is so great! Why should we use anything more complicated if it is not necessary?)
Another argument he makes in this video is that GPT doesn’t have long-term memory.
That's kinda true. GPT-3 only has a context window of 2048 tokens. However, I wouldn't say that GPT has no long-term memory. Actually, it already has a superhuman long-term memory. It only saw 44% of the Internet once and can already remember most of the stuff it looked at. I'm not aware of any human that could achieve that.
On the other hand, people can remember the context much longer than GPT can, so there is definitely some room for improvement.
Is George Hotz too confident with those answers? GPT-3 showed that it can not just memorize things, but can make real inferences and has a surprising tendency to task generalization. Maybe human intelligence is as simple as Cross-Entropy Loss? 🤷♂️
Of course, there are a bunch of other critics of the hypothesis out there. My goal was to collect the best arguments and objectively analyze them. If I missed any other major argument, please let me know!
Thoughts about the future of GPT
So, while it certainly seems like scaling the model will lead to further (maybe unexpected) performance gains, quite a few problems come up when we hypothesize a jump to AGI:
The current model has too little context-awareness. GPT-3 has a context window of 2048 tokens. Even if we scale up the language model and increase the context window while doing this, a scaled-up GPT-3 won't remember something that we told it a few weeks/months/years ago, as we humans can easily do.
We probably have to increase the sample efficiency so that we don’t run out of data (at least in the short term).
The good news is that some new model architectures are already available that could improve the next GPT version. As I explained in my GPT-3 paper presentation: GPT-3 is basically built on an outdated architecture from early 2018. For example, it didn't have any bidirectional pre-training such as BERT had.
So what is the argument against a future GPT-12 achieving human-level intelligence, once we figure out how to handle those issues?
If we increase the model in computation, dataset size, and parameters to the point where the model's prediction error becomes so low that its outputs rival that of a human (for any task you throw at it), how can we still say that the model doesn't truly understand everything?
Why is nobody building it?
So why does nobody train bidirectional multimodal Transformers with 100x the parameters and 100x the training data (consisting of images/video/text/pdf)?
Gwern's view on this is that companies like Google with DeepMind or other organizations that would have the resources and people to do just that, don't have the vision. They don't believe in the scaling hypothesis and are thinking too short-term. DeepMind in particular believes that to achieve AGI, they will have to find "the right algorithms" and just scaling models isn't the solution.
I understand this perspective too, if you have $10B to spend on building a language model, you could put the first $7B into research grants and just train a model with an advanced architecture for the remaining $3B. Or at least put the money into making parallel compute chips more efficient, so you don't waste too much energy.
In contrast to DeepMind, OpenAI can "bet the company" on this simple belief that the Scaling Hypothesis is true.
Who believes in the Scaling Hypothesis?
It's over 1 year since the GPT-3 paper got released. So who has the vision or is already building larger language models?
BAAI ("China's OpenAI", but with government funding) trained a 1.75 trillion parameters multi-modal model. Although it is a Mixture of Experts-Model and without going into too much detail on the specifics, a lot of AI researchers don’t count them, when comparing the parameter size of language models.
The South Korean Naver Corporation apparently build a model called “HyperCLOVA“ that is just slightly bigger than GPT-3 (204B parameters). We don’t have any idea how it benchmarks against GPT-3 though.
One of the biggest believers in the Scaling Hypothesis that I’m aware of is Connor Leahy. He is the Co-Founder of EleutherAI. A collective that is currently building an open-source GPT-3-like model called GPT-Neo. Unfortunately, they don’t have the resources right now to build a scaled-up version of GPT-3, but I’m sure that this smart group of hackers/researchers would have the skills and vision to do it (I highly recommend checking out their Discord)!
So 1 year after GPT-3 was released, nobody built a substantially bigger language model.
Conclusion
I'm not claiming that we will reach general intelligence by just scaling up GPT-3.
Even if it turns out that this approach won't achieve AGI, I'm certain that a 100x-1000x scaled-up version of GPT-3 will have some practical results that people are willing to pay for.
So why is nobody trying it? Or why are they so slow?
I can only assume that it is due to a lack of vision from companies that would have the resources to do it.
Sometimes bold claims (e.g. that we can achieve AGI through this) are necessary for rapid technological progress.
It is the same with Life Extension technologies. If scientists lack a vision or are scared of announcing that people will potentially live up to more than 1000 years, it prevents technological progress.
The war on cancer in the 1970s could only happen because scientists made bold claims about being able to save millions of lives. This is the main reason why so much funding went into the field. If every scientist would have been scared to talk about a future without cancer deaths, this fight would have never happened.
So I'm grateful for people like Gwern or Connor Leahy who are trying to push this forward, but it needs to get into the mainstream before we will see significant technological progress in this area!
Cheers,
Johannes
👋🏼 Endnote
Thanks for reading!